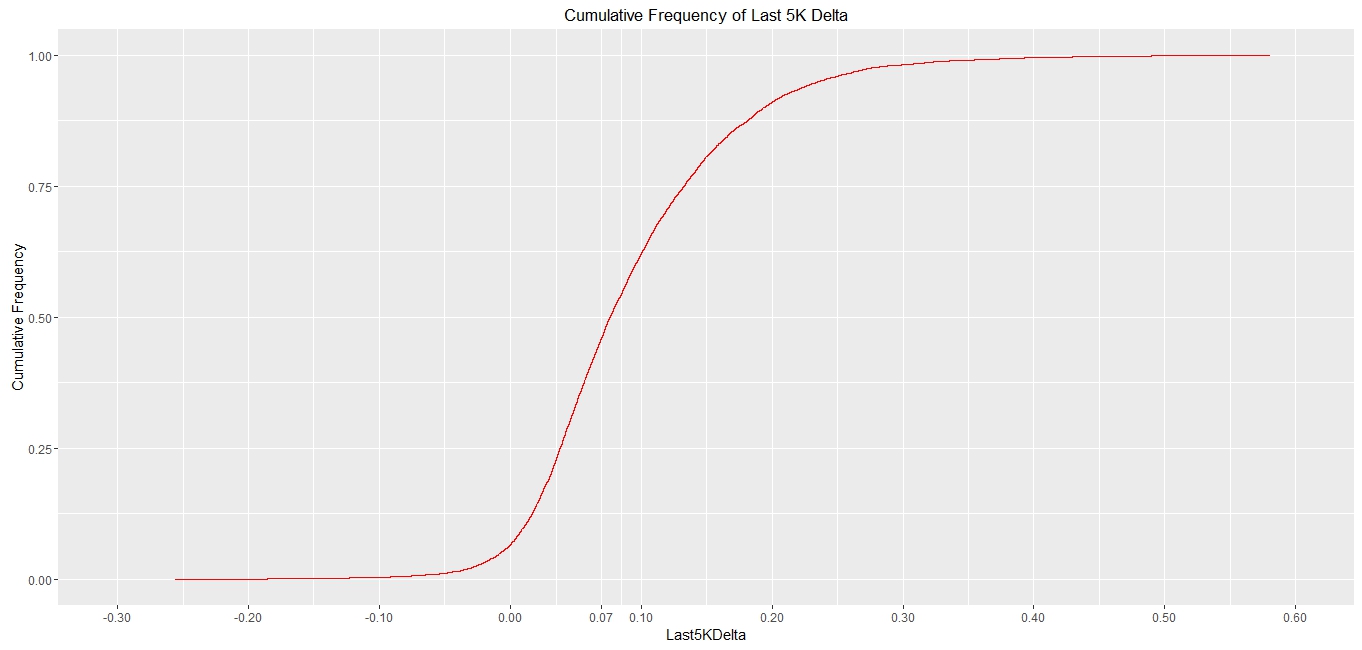
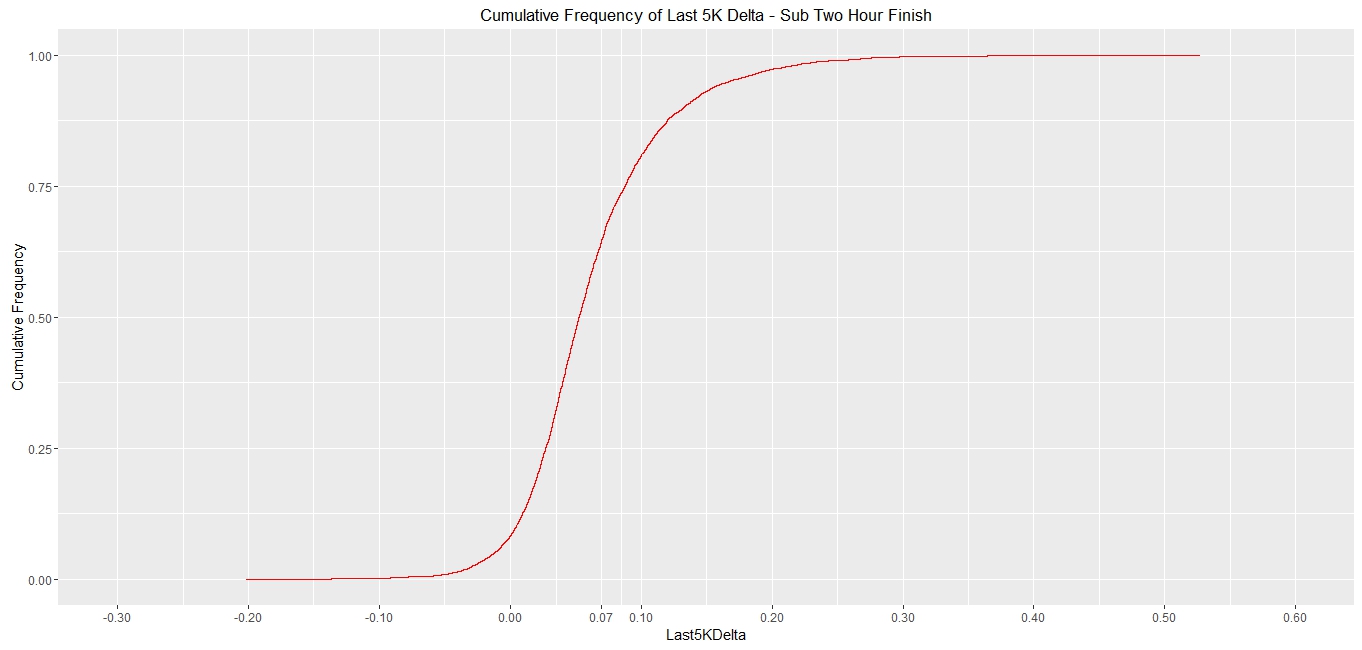
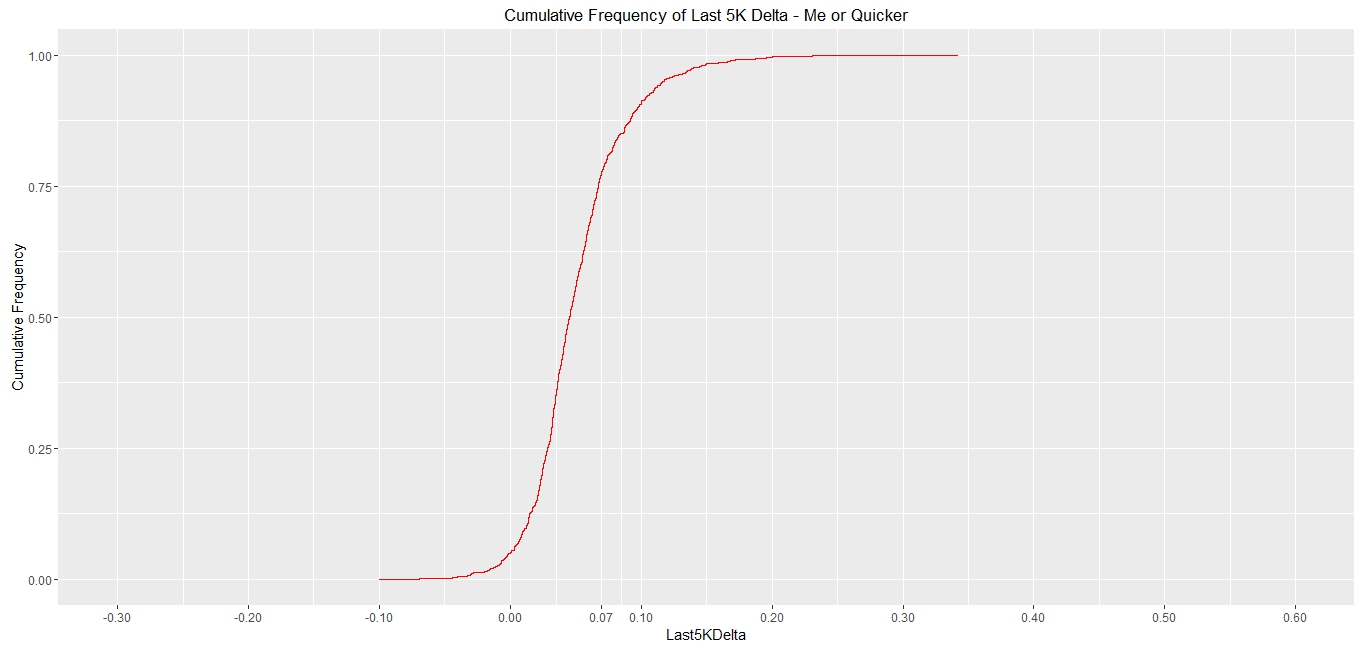
Now that was all very good and informative but:
- I analysed the Strava results manually. i.e. Stepped through the website and noted down dates, times and durations of runs.
- I used the Fitbit OAUTH1.0 URL builder website. Very manual and using OAUTH1.0, (since deprecated, see here on using OAUTH2.0).
Full code at the bottom of this post (to not interrupt the flow) but the algorithm is as follows:
- Loop, pulling back activity data from the Strava API (method here).
- Select each Strava run (i.e. filter out rides and swims) and log key details (start date/time, duration, name, distance)
- Double check if the date of the run was after I got my Fitbit (the FitbitEpoch constant). If it is, form the Fitbit API URL using date and time parameters derived from the Strava API output.
- Call the Fitbit API using the OAUTH2.0 method.
- Log the results for later processing.
This provides output like this:
pi@raspberrypi:~/Exercise/logs $ head steps_log_1.txt
2016-04-16T09:02:03Z_4899.7,Parkrun 20160416,1,09:02:00,100
2016-04-16T09:02:03Z_4899.7,Parkrun 20160416,2,09:03:00,169
2016-04-16T09:02:03Z_4899.7,Parkrun 20160416,3,09:04:00,170
2016-04-16T09:02:03Z_4899.7,Parkrun 20160416,4,09:05:00,171
2016-04-16T09:02:03Z_4899.7,Parkrun 20160416,5,09:06:00,172
2016-04-16T09:02:03Z_4899.7,Parkrun 20160416,6,09:07:00,170
2016-04-16T09:02:03Z_4899.7,Parkrun 20160416,7,09:08:00,170
2016-04-16T09:02:03Z_4899.7,Parkrun 20160416,8,09:09:00,170
2016-04-16T09:02:03Z_4899.7,Parkrun 20160416,9,09:10:00,168
2016-04-16T09:02:03Z_4899.7,Parkrun 20160416,10,09:11:00,170
So a date and time,name of the run, minute of run and step count.
So easy to filter out interesting runs to compare:
pi@raspberrypi:~/Exercise/logs $ grep 20150516 steps_log_1.txt > parkrun_steps_1.txt
pi@raspberrypi:~/Exercise/logs $ grep 20160416 steps_log_1.txt >> parkrun_steps_1.txt
Then import to R for post analysis and plotting:
> parkrun1 <- read.csv(file=file.choose(),head=FALSE,sep=",")
> colnames(parkrun1) <- c("DateTimeDist","Name","Minute","TimeOfDay","Steps")
> head(parkrun1)
DateTimeDist Name Minute TimeOfDay Steps
1 2015-05-16T09:00:00Z_5000.0 Naked Winchester Parkrun 20150516 1 09:00:00 85
2 2015-05-16T09:00:00Z_5000.0 Naked Winchester Parkrun 20150516 2 09:01:00 105
3 2015-05-16T09:00:00Z_5000.0 Naked Winchester Parkrun 20150516 3 09:02:00 107
4 2015-05-16T09:00:00Z_5000.0 Naked Winchester Parkrun 20150516 4 09:03:00 136
5 2015-05-16T09:00:00Z_5000.0 Naked Winchester Parkrun 20150516 5 09:04:00 162
6 2015-05-16T09:00:00Z_5000.0 Naked Winchester Parkrun 20150516 6 09:05:00 168
library(ggplot2)
> ggplot(data = parkrun1, aes(x = Minute, y = Steps, color = Name))
+ geom_point() + geom_line()
+ labs(x="Minute", y="Steps") + ggtitle("Running Cadence - Parkrun")
> ggplot(data = parkrun1, aes(x = Minute, y = Steps, color = Name))
+ geom_point() + geom_line()
+ labs(x="Minute", y="Steps") + ggtitle("Running Cadence - Parkrun")
Yielding this graph:

Interesting that I took longer to get going on the 2015 run, maybe there was congestion at the start. The key thing I was looking for was the "steady state" cadence comparison between 2015 and 2016. It's higher in 2016 which is exactly what I wanted to see as it's something I've worked on improving.
Using the same method I plotted the chart below which shows a long run prior to a half-marathon then the half-marathon itself:

Now this is interesting. The cadence was slightly higher for the whole of the training run (blue line) and much more consistent. For the half-marathon itself (red line) my cadence really tailed off which is in tune with my last post where I analysed my drop off in speed over the final quarter of the run.
Here's all the code. Modify for your API credentials, file system and Fitbit "Epoch" accordingly:
Interesting that I took longer to get going on the 2015 run, maybe there was congestion at the start. The key thing I was looking for was the "steady state" cadence comparison between 2015 and 2016. It's higher in 2016 which is exactly what I wanted to see as it's something I've worked on improving.
Using the same method I plotted the chart below which shows a long run prior to a half-marathon then the half-marathon itself:

Now this is interesting. The cadence was slightly higher for the whole of the training run (blue line) and much more consistent. For the half-marathon itself (red line) my cadence really tailed off which is in tune with my last post where I analysed my drop off in speed over the final quarter of the run.
pi@raspberrypi:~/Exercise $ more strava_fitbit_v1.py
#here's a typical Fitbit API URL
#FitbitURL = "https://api.fitbit.com/1/user/-/activities/steps/date/2016-01-31/1d/1min/time/09:00/09:15.json"
import urllib2
import base64
import json
from datetime import datetime, timedelta
import time
import urllib
import sys
import os
#The base URL we use for activities
BaseURLActivities = "https://www.strava.com/api/v3/activities?access_token=<Strava_Token_Here>per_page=200&page="
StepsLogFile = "/home/pi/Exercise/logs/steps_log_1.txt"
#Start element of Fitbit URL
FitbitURLStart = "https://api.fitbit.com/1/user/-/activities/steps/date/"
#Other constants
MyFitbitEpoch = "2015-01-26"
#Use this URL to refresh the access token
TokenURL = "https://api.fitbit.com/oauth2/token"
#Get and write the tokens from here
IniFile = "/home/pi/Exercise/tokens.txt"
#From the developer site
OAuthTwoClientID = "FitBitClientIDHere"
ClientOrConsumerSecret = "FitbitSecretHere"
#Some contants defining API error handling responses
TokenRefreshedOK = "Token refreshed OK"
ErrorInAPI = "Error when making API call that I couldn't handle"
#Get the config from the config file. This is the access and refresh tokens
def GetConfig():
print "Reading from the config file"
#Open the file
FileObj = open(IniFile,'r')
#Read first two lines - first is the access token, second is the refresh token
AccToken = FileObj.readline()
RefToken = FileObj.readline()
#Close the file
FileObj.close()
#See if the strings have newline characters on the end. If so, strip them
if (AccToken.find("\n") > 0):
AccToken = AccToken[:-1]
if (RefToken.find("\n") > 0):
RefToken = RefToken[:-1]
#Return values
return AccToken, RefToken
def WriteConfig(AccToken,RefToken):
print "Writing new token to the config file"
print "Writing this: " + AccToken + " and " + RefToken
#Delete the old config file
os.remove(IniFile)
#Open and write to the file
FileObj = open(IniFile,'w')
FileObj.write(AccToken + "\n")
FileObj.write(RefToken + "\n")
FileObj.close()
#Make a HTTP POST to get a new
def GetNewAccessToken(RefToken):
print "Getting a new access token"
#RefToken = "e849e1545d8331308eb344ce27bc6b4fe1929d8f1f9f3a056c5636311ba49014"
#Form the data payload
BodyText = {'grant_type' : 'refresh_token',
'refresh_token' : RefToken}
#URL Encode it
BodyURLEncoded = urllib.urlencode(BodyText)
print "Using this as the body when getting access token >>" + BodyURLEncoded
#Start the request
tokenreq = urllib2.Request(TokenURL,BodyURLEncoded)
#Add the headers, first we base64 encode the client id and client secret with a : inbetween and create the authorisation header
tokenreq.add_header('Authorization', 'Basic ' + base64.b64encode(OAuthTwoClientID + ":" + ClientOrConsumerSecret))
tokenreq.add_header('Content-Type', 'application/x-www-form-urlencoded')
#Fire off the request
try:
tokenresponse = urllib2.urlopen(tokenreq)
#See what we got back. If it's this part of the code it was OK
FullResponse = tokenresponse.read()
#Need to pick out the access token and write it to the config file. Use a JSON manipluation module
ResponseJSON = json.loads(FullResponse)
#Read the access token as a string
NewAccessToken = str(ResponseJSON['access_token'])
NewRefreshToken = str(ResponseJSON['refresh_token'])
#Write the access token to the ini file
WriteConfig(NewAccessToken,NewRefreshToken)
print "New access token output >>> " + FullResponse
except urllib2.URLError as e:
#Gettin to this part of the code means we got an error
print "An error was raised when getting the access token. Need to stop here"
print e.code
print e.read()
sys.exit()
#This makes an API call. It also catches errors and tries to deal with them
def MakeAPICall(InURL,AccToken,RefToken):
#Start the request
req = urllib2.Request(InURL)
#Add the access token in the header
req.add_header('Authorization', 'Bearer ' + AccToken)
print "I used this access token " + AccToken
#Fire off the request
try:
#Do the request
response = urllib2.urlopen(req)
#Read the response
FullResponse = response.read()
#Return values
return True, FullResponse
#Catch errors, e.g. A 401 error that signifies the need for a new access token
except urllib2.URLError as e:
print "Got this HTTP error: " + str(e.code)
HTTPErrorMessage = e.read()
print "This was in the HTTP error message: " + HTTPErrorMessage
#See what the error was
if (e.code == 401) and (HTTPErrorMessage.find("Access token invalid or expired") > 0):
GetNewAccessToken(RefToken)
return False, TokenRefreshedOK
elif (e.code == 401) and (HTTPErrorMessage.find("Access token expired") > 0):
GetNewAccessToken(RefToken)
return False, TokenRefreshedOK
#Return that this didn't work, allowing the calling function to handle it
return False, ErrorInAPI
#This function takes a date and time and checks whether it's after a given date
def CheckAfterFitbit(InDateTime):
#See how many days there's been between today and my first Fitbit date.
StravaDate = datetime.strptime(InDateTime,"%Y-%m-%dT%H:%M:%SZ") #First Fitbit date as a Python date object
FitbitDate = datetime.strptime(MyFitbitEpoch,"%Y-%m-%d") #Last Fitbit date as a Python date object
#See if the provided date is greater than the Fitbit date. If so, return True, else return false
if ((StravaDate - FitbitDate).days > -1):
return True
else:
return False
#Forms the full URL to use for Fitbit. Example:
#https://api.fitbit.com/1/user/-/activities/steps/date/2016-01-31/1d/1min/time/09:00/09:15.json
def FormFitbitURL(URLSt,DtTmSt,Dur):
#First we need to add the date component which should be the first part of the date and time string we got from Strava. Add the next few static bits as well
FinalURL = URLSt + DtTmSt[0:10] + "/1d/1min/time/"
#Now add the first time part which is also provided as a parameter. This will take us back to the start of the minute STrava started which is what we want
FinalURL = FinalURL + DtTmSt[11:16] + "/"
#Now we need to compute the end time which needs a bit of maths as we need to turn the start date into a Python date object and then add on elapsed seconds,
#turn back to a string and take the time part
StravaStartDateTime = datetime.strptime(DtTmSt,"%Y-%m-%dT%H:%M:%SZ")
#Now add elapsed time using time delta function
StravaEndDateTime = StravaStartDateTime + timedelta(seconds=int(Dur))
EndTimeStr = str(StravaEndDateTime.time())
#Form the final URL
FinalURL = FinalURL + EndTimeStr[0:5] + ".json"
return FinalURL
#@@@@@@@@@@@@@@@@@@@@@@@@@@@This is the main part of the code
#Open the file to use
MyFile = open(StepsLogFile,'w')
#Loop extracting data. Remember it comes in pages. Initialise variables first, including the tokens to use
EndFound = False
LoopVar = 1
AccessToken = ""
RefreshToken = ""
#Get the tokens from the config file
AccessToken, RefreshToken = GetConfig()
#Main loop - Getting all activities
while (EndFound == False):
#Do a HTTP Get - First form the full URL
ActivityURL = BaseURLActivities + str(LoopVar)
StravaJSONData = urllib2.urlopen(ActivityURL).read()
if StravaJSONData != "[]": #This checks whether we got an empty JSON response and so should end
#Now we process the JSON
ActivityJSON = json.loads(StravaJSONData)
#Loop through the JSON structure
for JSONActivityDoc in ActivityJSON:
#See if it was a run. If so we're interested!!
if (str(JSONActivityDoc["type"]) == "Run"):
#We want to grab a date, a start time and a duration for the Fitbit API. We also want to grab a distance which we'll use as a grpah legend
print "@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@"
StartDateTime = str(JSONActivityDoc["start_date_local"])
StravaDuration = str(JSONActivityDoc["elapsed_time"])
StravaDistance = str(JSONActivityDoc["distance"])
StravaName = str(JSONActivityDoc["name"])
#See if it's after 2015-01-26 which is when I got my Fitbit
if CheckAfterFitbit(StartDateTime):#Tell the user what we're doing
print "Strava Date and Time: " + StartDateTime
print "Strava Duration: " + StravaDuration
print "Strava Distance: " + StravaDistance
#Form the URL to use for Fitbit
FitbitURL = FormFitbitURL(FitbitURLStart,StartDateTime,StravaDuration)
print "Am going to call FitbitAPI with: " + FitbitURL
#Make the API call
APICallOK, APIResponse = MakeAPICall(FitbitURL, AccessToken, RefreshToken)
#See how this came back.
if not APICallOK: #An error in the response. If we refreshed tokens we go again. Else we exit baby!
if (APIResponse == TokenRefreshedOK):
#Just make the call again
APICallOK, APIResponse = MakeAPICall(FitbitURL, AccessToken, RefreshToken)
else:
print "An error occurred when I made the Fitbit API call. Going to have to exit"
sys.exit(0)
#If we got to this point then we must have got an OK response. We need to process this into the text file. Format is:
#Date_Distance,MinuteWithinRun,Time,Steps
#print APIResponse
ResponseAsJSON = json.loads(APIResponse)
MinNum = 1 #Use this to keep track of the minute within the run, incrementing each time
for StepsJSON in ResponseAsJSON["activities-steps-intraday"]["dataset"]:
OutString = StartDateTime + "_" + StravaDistance + "," + StravaName + "," + str(MinNum) + "," + str(StepsJSON["time"]) + "," + str(StepsJSON["value"]) + "\r\n"
#Write to file
MyFile.write(OutString)
#Increment the loop var
MinNum += 1
#Set up for next loop
LoopVar += 1
else:
EndFound = True
#Close the log file
MyFile.close()